AI clusters have totally reworked the best way visitors flows inside information facilities. More often than not, visitors now strikes east–west between GPUs throughout mannequin coaching and checkpointing, slightly than north–south between functions and the web. This means a shift in the place bottlenecks happen. CPUs, which had been as soon as liable for encapsulation, circulation management, and safety, at the moment are on the essential path. This provides latency and variability that makes IT tougher to make use of GPUs.
Attributable to this efficiency restrict, the DPU/SmartNIC has developed from being an non-obligatory accelerator to changing into essential infrastructure. “Information heart is the brand new unit of computing,” NVIDIA CEO Jensen Huang mentioned through the GTC 2021. “There’s no approach you’re going to do this on the CPU. So it’s a must to transfer the networking stack off. You need to transfer the safety stack off, and also you need to transfer the info processing and information motion stack off.” Jensen Huang, interview with The Next Platform. NVIDIA claims its Spectrum-X Ethernet cloth (encompassing congestion management, adaptive routing, and telemetry) can deliver up to 48% higher storage read bandwidth for AI workloads.
The community interface is now a layer that processes issues. The query of maturity is now not whether or not offloading is important, however which offloads at the moment present a measurable operational ROI.
The place AI Material Site visitors and Reliability Grow to be Vital
AI workloads function synchronously: when one node experiences congestion, all GPUs within the cluster wait. Meta stories that routing-induced circulation collisions and uneven visitors distribution in early RoCE deployments “degraded the training performance up to more than 30%,” prompting modifications in routing and collective tuning. These points are usually not purely architectural; they emerge immediately from how east–west flows behave at scale.
InfiniBand has lengthy supplied credit-based link-level circulation management (per-VL) to ensure lossless supply and stop buffer overruns, i.e., a {hardware} mechanism constructed into the hyperlink layer. Ethernet is evolving alongside comparable traces by means of the Extremely Ethernet Consortium (UEC): its Extremely Ethernet Transport (UET) work introduces endpoint/host-aware transport, congestion administration guided by real-time suggestions, and coordination between endpoints and switches, explicitly transferring extra congestion dealing with and telemetry into the NIC/endpoint.
InfiniBand stays the benchmark for deterministic cloth habits. Ethernet-based AI materials are quickly evolving by means of improvements in UET and SmartNIC.
Community professionals should consider silicon capabilities, not simply hyperlink speeds. Reliability is now decided by telemetry, congestion management, and offload assist on the NIC/DPU stage.
Additionally Learn: Smarter DevOps with Kite: AI Meets Kubernetes
Offload Sample: Encapsulation and Stateless Pipeline Processing
AI clusters at cloud and enterprise scale depend on overlays similar to VXLAN and GENEVE to section visitors throughout tenants and domains. Historically, these encapsulation duties run on the CPU.
DPUs and SmartNICs offload encapsulation, hashing, and circulation matching immediately into {hardware} pipelines, lowering jitter and liberating CPU cycles. NVIDIA paperwork VXLAN {hardware} offloads on its NICs/DPUs and claims Spectrum-X delivers material AI-fabric gains, including up to 48% greater storage learn bandwidth in associate assessments and greater than 4x decrease latency versus conventional Ethernet in Supermicro benchmarking.
Offload for VXLAN and stateless circulation processing is supported throughout NVIDIA BlueField, AMD Pensando Elba, and Marvell OCTEON 10 platforms.
From a aggressive perspective:
- NVIDIA focuses on integrating tightly with Datacenter Infrastructure-on-a-Chip (DOCA) for GPU-accelerated AI workloads.
- AMD Pensando provides P4 programmability and integration with Cisco Good Switches.
- Intel IPU brings Arm-heavy designs for transport programmability.
Encapsulation offload is now not a efficiency enhancer; IT is foundational for predictable AI cloth habits.
Offload Sample: Inline Encryption and East–West Safety
As AI fashions cross sovereign boundaries and multi-tenant clusters turn out to be frequent, encryption of east–west visitors has turn out to be obligatory. Nonetheless, encrypting this visitors within the host CPU introduces measurable efficiency penalties. In a joint VMware–6WIND–NVIDIA validation, BlueField-2 DPUs offloaded IPsec for a 25 Gbps testbed (2×25 GbE BlueField-2), demonstrating greater throughput and decrease host-CPU use for the 6WIND vSecGW on vSphere 8.

Determine: Due to NVIDIA
Marvell positions its OCTEON 10 DPUs for inline safety offload in AI information facilities, citing built-in crypto accelerators able to 400+ Gbps IPsec/TLS (Marvell OCTEON 10 DPU Household media deck); the corporate additionally highlights rising AI-infrastructure demand in its investor communications. Encryption offload is shifting from non-obligatory to required as AI turns into regulated infrastructure.
Offload Sample: Microsegmentation and Distributed Firewalling
GPU servers are sometimes deployed in high-trust zones, however there are nonetheless dangers of lateral motion, particularly in environments with many tenants or when inference is completed on shared infrastructure. Conventional firewalls are configured outdoors the GPUs and drive east–west visitors by means of centralized choke factors. This bottleneck contributes to elevated latency and creates blind spots in operations.
DPUs and SmartNICs now allow you to arrange L4 firewalls immediately on the NIC, implementing coverage on the supply. Cisco introduced the N9300 Series “Smart Switches,” which have programmable DPUs that add stateful companies on to the info heart cloth to hurry up operations. NVIDIA’s BlueField DPU equally helps microsegmentation, permitting operators to use Zero Belief ideas to GPU workloads with out involving the host CPU.
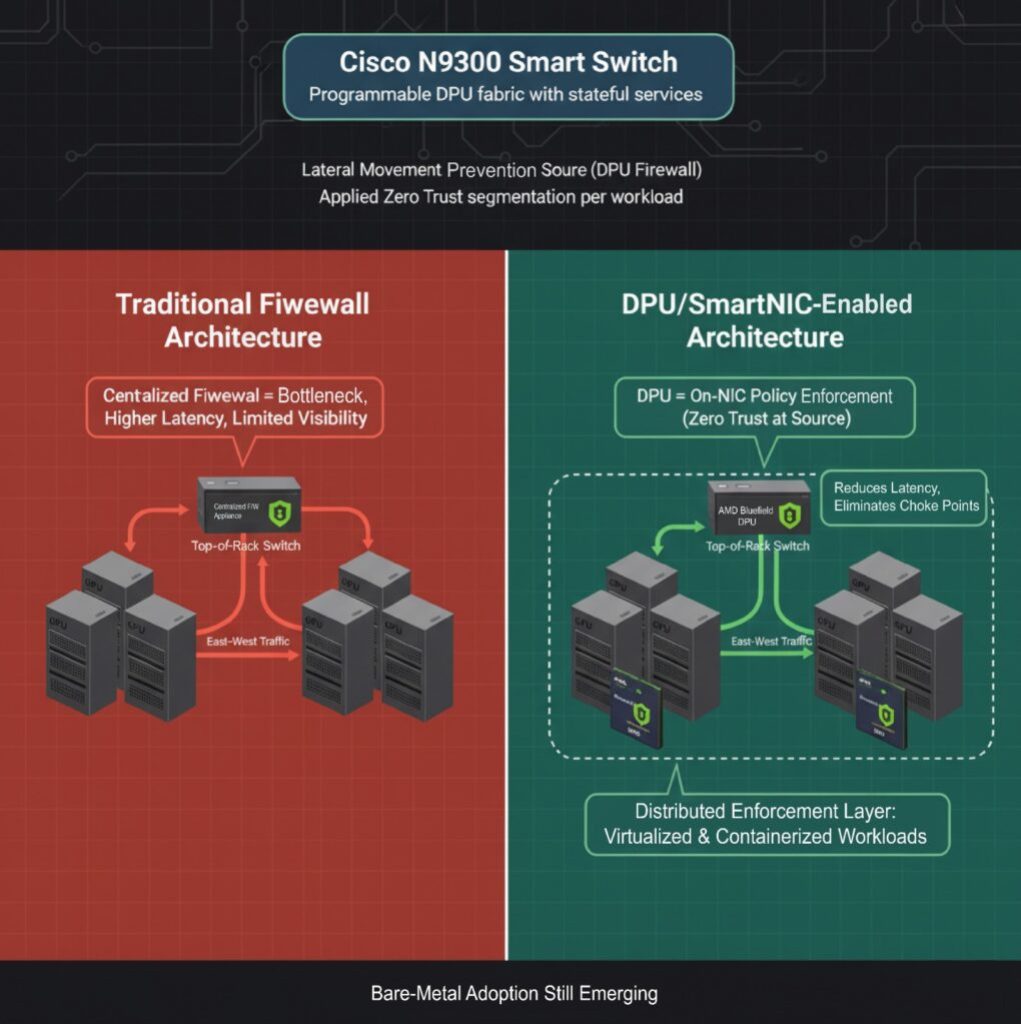
Whereas firewall offload is production-ready for virtualized and containerized environments, its software in bare-metal AI cloth deployments continues to be growing.
Community engineers achieve a brand new enforcement level contained in the server itself. This offload sample is gaining traction in regulated and sovereign AI deployments the place east–west isolation is required.
Additionally Learn: Agentic AI vs AI Brokers: Key Variations & Influence on the Way forward for AI
Case Snapshot: Ethernet AI Material Operations in Manufacturing
To beat cloth instability, Meta co-designed the transport layer and collective library, implementing Enhanced ECMP visitors engineering, queue-pair scaling, and a receiver-driven admission mannequin. These modifications yielded up to 40% improvement in AllReduce completion latency, demonstrating that cloth efficiency is now decided as a lot by transport logic within the NIC as by change structure.
In one other instance, a joint VMware–6WIND–NVIDIA validation, BlueField-2 DPUs offloaded IPsec for a 6WIND vSecGW on vSphere 8. The lab setup (restricted by BlueField-2’s dual-25 GbE ports) focused and demonstrated no less than 25 Gbps aggregated IPsec throughput and confirmed that offloading elevated throughput and improved software response, whereas liberating host-CPU cores.
Actual deployments validate efficiency good points. Nonetheless, unbiased benchmarks evaluating distributors stay restricted. Community architects ought to consider vendor claims by means of the lens of revealed deployment proof, slightly than counting on advertising figures.
Purchaser’s Panorama: Silicon and SDK Maturity
The aggressive panorama is being reworked by DPU and SmartNIC methods. The next desk highlights key concerns and variations amongst numerous distributors.
| Vendor | Differentiator | Maturity | Key Concerns |
| NVIDIA | Tight integration with GPUs, DOCA SDK, and superior telemetry | Excessive | Highest efficiency; ecosystem lock-in is a priority |
| AMD Pensando | P4-based pipeline, Cisco integration | Excessive | Sturdy in enterprise and hybrid deployments |
| Intel IPU | Programmable transport, crypto acceleration | Rising | Anticipated 2025 rollout; backed by Google deployment historical past |
| Marvell OCTEON | Energy-efficient, storage-centric offload | Medium | Power in edge and disaggregated storage AI |
Consumers are prioritizing greater than uncooked speeds and feeds. Omdia emphasizes that effective operations now hinge on AI-driven automation and actionable telemetry, not simply greater hyperlink charges.
Procurement choices have to be aligned not solely with efficiency targets however with SDK roadmap maturity and long-term platform lock-in dangers.
Aggressive and Architectural Selections: What Operators Should Determine
As AI materials transfer from early deployment to scaled manufacturing, infrastructure leaders are confronted with a number of strategic choices that may form value, efficiency, and operational threat for years to return.
DPU vs. SuperNIC vs. Excessive-Finish NIC
DPUs ship you Arm cores, crypto blocks, and storage/community offload capabilities. They work greatest in AI environments which have a number of tenants, are regulated, or are delicate to safety. SuperNICs, like NVIDIA’s Spectrum-X adapters, are designed to work with switches with very low latency and deep telemetry integration, however they lack general-purpose processors.
Excessive-end NICs (with out offload capabilities) should serve single-tenant or small-scale AI clusters, however lack long-term viability for multi-pod AI materials.
Ethernet vs. InfiniBand for AI Materials
InfiniBand continues to be the perfect at native congestion management and predictable latency. Nonetheless, Ethernet is rapidly gaining popularity as distributors standardize Extremely Ethernet Transport and add SmartNIC/DPU offload. InfiniBand is your best option for hyperscale deployments the place you settle for vendor lock-in.
“Once we first initiated our protection of AI Again-end Networks in late 2023, the market was dominated by InfiniBand, holding over 80 p.c share… Because the business strikes to 800 Gbps and past, we imagine Ethernet is now firmly positioned to overhaul InfiniBand in these high-performance deployments.” Sameh Boujelbene, Vice President, Dell’Oro Group.
SDK and Ecosystem Management
Vendor management over software program ecosystems is changing into a key differentiator. NVIDIA DOCA, AMD’s P4-based framework, and Intel’s IPU SDK every symbolize divergent improvement paths. Selecting a vendor right this moment successfully means selecting a programming mannequin and long-term integration technique.
Additionally Learn: How AI Chatbots Can Assist Streamline Your Enterprise Operations?
IT-pencils-out-and-what-to-watch-next”>When IT Pencils Out and What to Watch Subsequent
DPUs and SmartNICs are now not positioned as future enablers. They’re changing into a required infrastructure for AI-scale networking. The enterprise case is most clear in clusters the place:
- East–west visitors dominates
- GPU utilization is affected by microburst congestion
- Regulatory or multi-tenant necessities mandate encryption or isolation
- Storage visitors interferes with compute efficiency
Early adopters report measurable ROI. NVIDIA disclosed improved GPU utilization and a 48% enhance in sustained storage throughput in Spectrum-X deployments that mix telemetry and congestion offload. In the meantime, Marvell and AMD report rising connect charges for DPUs in AI design wins the place operators require information path autonomy from the host CPU.
Over the following 12 months, community professionals ought to carefully monitor:
- NVIDIA’s roadmap for BlueField-4 and SuperNIC enhancements
- AMD Pensando’s Salina DPUs built-in into Cisco Good Switches
- UEC 1.0 specification and vendor adoption timelines
- Intel’s first manufacturing deployments of the E2200 IPU
- Unbiased benchmarks evaluating Ethernet Extremely Material vs. InfiniBand efficiency beneath AI collective hundreds
The economics of AI networking now hinge on the place processing occurs. The strategic shift is underway from CPU-centric architectures to materials the place DPUs and SmartNICs outline efficiency, reliability, and safety at scale.
👇Observe extra 👇
👉 bdphone.com
👉 ultractivation.com
👉 trainingreferral.com
👉 shaplafood.com
👉 bangladeshi.help
👉 www.forexdhaka.com
👉 uncommunication.com
👉 ultra-sim.com
👉 forexdhaka.com
👉 ultrafxfund.com
👉 bdphoneonline.com
👉 dailyadvice.us